OpenAI’s Privacy Filter vs Protegrity-PII and the Data Lesson As Old As Time
PII detection: where it matters and why it’s hard
Personally identifiable information (PII) is any piece of information that can be used to identify and/or extract information about an individual. PII frequently shows up in free-form text in the form of names, email addresses, phone numbers, and government IDs, to list a few that are uniquely tied to a sole person. The less obvious forms of PII include things like ZIP codes, job titles, employer names, or rare diagnoses, which on the surface look harmless, but in combination with one another, can pin down a single individual. As such, PII detection is at the forefront of data security companies.
For many companies, PII can live in a variety of locations; whether that be in databases or in free-form text logs. As such, leaks in PII can occur across numerous pipelines, which necessitates an accurate PII detector that can find PII within these pipelines and alert users where it exists. Without such a detector, PII, especially nowadays in the agentic era, can unintentionally leak to the public. In critical sectors such as banking and healthcare, leaks of PII have large downstream effects, including regulatory and legal consequences (GDPR, HIPAA, CCPA), as well as large brand fallout and loss in trust. Furthermore, in these regulated industries, the service provider for PII detection is legally responsible for any mishaps. This makes the mission of accurate and scalable PII detection all the more integral.
The reason PII detection is hard starts with the data itself. First, most PII doesn’t follow a specific or easy to identify pattern. Unlike a credit card number or a Social Security number, a name is just a word. So is a street or address. Lightweight tools like regex can’t help you here, because there’s nothing structurally distinctive to match against, so catching these requires an understanding of language and the subtle cues humans pick up on without thinking. Second, different industries also use different identifier schemas , such as for part ID numbers or health insurance ID numbers. As such, a detector that looks excellent on a generic public benchmark can fall over on real-world hospital correspondence, banking statements, or legal filings.
Underneath all of this is a classic chicken-and-egg problem. To train a strong detector you need a large and accurately labeled corpus of documents that contain PII. This almost surely cannot exist in practice. Real customer documents cannot be shared for privacy and legal reasons. Consequently, those interested in PII detection resort to generating synthetic data instead. Synthetic data sidesteps the privacy problem, as in principle no real entities such as names, are being used, but introduces a labelling problem of its own. We now need to either have our engineers hand label hundreds of thousands of data points (not happening, for us at least) or use programmatic ways to label the data (which has known issues such as entity span misalignment). The end result is a strange loop. To build a good PII detector, you need labeled data, but labeling that data sufficiently almost boils down to the same task as the one you’re trying to solve in the first place.
OpenAI releases Privacy Filter
Last month, OpenAI released Privacy Filter (OPF), a small open-weights model trained to find PII in free-form text. It can be ran on a local machine and furthermore reports a headline F1 of 0.96 on the public PII-Masking-300k benchmark. As such, PII teams across the enterprise space have been scrambling to figure out what this means for their stacks. As one such team here at Protegrity, we launched an internal investigation against our models, procedures, and datasets and detail such findings herein.
The short version, and the spoiler for the rest of the post, is that PII detection (and arguably many problems in the ML-sphere) is way more of a high-quality data generation problem than it is a model architecture problem. Critically, OPF is an open-weights release rather than an open-source one, so what the community gets is the trained model and not the training dataset/dataset generation pipeline. That is a perfectly reasonable choice on OpenAI’s part, but crucially, this means that their core contribution lives squarely at the model architecture. The dataset design and generation is still on individual teams/companies to solve for themselves. And it is precisely this design that is vital for downstream performance.
With that framing in place, the natural next question to investigate pertains to what the comparison between OPF and our in-house detector actually looks like once you put both models on the same data and score them the same way. We start with a toy example of the kind of enterprise text that a production PII detector sees in the real world and conclude on a comparison against the public benchmarks OPF reports on.
Knowledge extraction via from PII detector
Here at Protegrity, we are spending a great time thinking about and classifying what is knowledge. This has resulted in a myriad of technical and, at times, philosophical discussions.
Before getting into the standard benchmarks and discussions for PII classification, we want to ground the discussion in a concrete threat that can happen in production. The question we seek to investigate here is: what does an attacker actually do with the output of a PII detector, and what happens when that detector has imperfections? The example below walks through one such scenario.
Below is an data point that we ran through both our internal PII detector (Protegrity-PII) and the OPF classifier from our internal test dataset (synthetic example). Imagine you are processing healthcare correspondence, and a letter comes in with the following opener:
Subject is a Cambridge resident and former Governor of Massachusetts, sex M, born 1945-07-31, admitted 1996-05-18.When we feed this text into both classifiers and perform redaction on the detected entities, we see:
OPF:
Subject is a Cambridge resident and former Governor of Massachusetts, sex M, born [PRIVATE_DATE], admitted [PRIVATE_DATE].Protegrity-PII:
Subject is a [PRIVATE_ADDRESS] resident and former Governor of [PRIVATE_ADDRESS], sex [PRIVATE_PERSON], born [PRIVATE_DATE], admitted [PRIVATE_DATE].Now what can we do with this information?
In this fictitious scenario, imagine we are an attacker and we’ve received back the text from both PII detectors. For the sake of this scenario, assume we have access to two databases: one that details state governors in the USA and one that details current residents of Massachusetts.
DB1 · US State Governors
| name | party | term_start | term_end | sex | dob | state_served |
|---|---|---|---|---|---|---|
| Maura T. Healey | Democratic | 2023 | 2026 | F | 1971-02-08 | MA |
| Edward J. King | Democratic | 1979 | 1983 | M | 1925-05-11 | MA |
| Gray L. Davis | Democratic | 1999 | 2003 | M | 1942-12-26 | CA |
| Phil D. Murphy | Democratic | 2018 | 2026 | M | 1957-08-16 | NJ |
| Christopher J. Christie | Republican | 2010 | 2018 | M | 1962-09-06 | NJ |
| Andrew M. Cuomo | Democratic | 2011 | 2021 | M | 1957-12-06 | NY |
| Christian A. Herter | Republican | 1953 | 1957 | M | 1895-03-28 | MA |
| Jane M. Swift | Republican | 2001 | 2003 | F | 1965-02-24 | MA |
| Paul A. Dever | Democratic | 1949 | 1953 | M | 1903-01-15 | MA |
| Tom W. Corbett | Republican | 2011 | 2015 | M | 1949-06-17 | PA |
| Tom W. Wolf | Democratic | 2015 | 2023 | M | 1948-11-17 | PA |
| George E. Deukmejian | Republican | 1983 | 1991 | M | 1928-06-06 | CA |
| Endicott Peabody | Democratic | 1963 | 1965 | M | 1920-02-15 | MA |
| William F. Weld | Republican | 1991 | 1997 | M | 1945-07-31 | MA |
| Hugh L. Carey | Democratic | 1975 | 1982 | M | 1919-04-11 | NY |
| Ron D. DeSantis | Republican | 2019 | 2026 | M | 1978-09-14 | FL |
| Robert F. Bradford | Republican | 1947 | 1949 | M | 1902-12-15 | MA |
| Arnold A. Schwarzenegger | Republican | 2003 | 2011 | M | 1947-07-30 | CA |
| James E. McGreevey | Democratic | 2002 | 2004 | M | 1957-08-06 | NJ |
| Rick L. Scott | Republican | 2011 | 2019 | M | 1952-12-01 | FL |
| Mario M. Cuomo | Democratic | 1983 | 1994 | M | 1932-06-15 | NY |
| Jeb E. Bush | Republican | 1999 | 2007 | M | 1953-02-11 | FL |
| Rick J. Perry | Republican | 2000 | 2015 | M | 1950-03-04 | TX |
| George E. Pataki | Republican | 1995 | 2006 | M | 1945-06-24 | NY |
| George W. Bush | Republican | 1995 | 2000 | M | 1946-07-06 | TX |
| John A. Volpe | Republican | 1965 | 1969 | M | 1908-12-08 | MA |
| Ann W. Richards | Democratic | 1991 | 1995 | F | 1933-09-01 | TX |
| Greg W. Abbott | Republican | 2015 | 2026 | M | 1957-11-13 | TX |
| Charlie M. Crist | Republican | 2007 | 2011 | M | 1956-07-24 | FL |
| W. Mitt Romney | Republican | 2003 | 2007 | M | 1947-03-12 | MA |
| Michael S. Dukakis | Democratic | 1975 | 1979 | M | 1933-11-03 | MA |
| Maurice J. Tobin | Democratic | 1945 | 1947 | M | 1901-05-22 | MA |
| Robert P. Casey | Democratic | 1987 | 1995 | M | 1932-01-09 | PA |
| Pete B. Wilson | Republican | 1991 | 1999 | M | 1933-08-23 | CA |
| Francis W. Sargent | Republican | 1969 | 1975 | M | 1915-07-29 | MA |
| Edward G. Rendell | Democratic | 2003 | 2011 | M | 1944-01-05 | PA |
| Charles D. Baker | Republican | 2015 | 2023 | M | 1956-11-13 | MA |
| Deval L. Patrick | Democratic | 2007 | 2015 | M | 1956-07-31 | MA |
| Edmund G. Brown Jr. | Democratic | 1975 | 1983 | M | 1938-04-07 | CA |
| Foster Furcolo | Democratic | 1957 | 1961 | M | 1911-07-29 | MA |
| Nelson A. Rockefeller | Republican | 1959 | 1973 | M | 1908-07-08 | NY |
DB2 · Massachusetts Residential Roll
| name | sex | dob | city | state | zip |
|---|---|---|---|---|---|
| Deval L. Patrick | M | 1956-07-31 | Milton | MA | 02186 |
| Michael S. Dukakis | M | 1933-11-03 | Brookline | MA | 02446 |
| George N. Yost | M | 1952-04-15 | Cambridge | MA | 02139 |
| W. Mitt Romney | M | 1947-03-12 | Belmont | MA | 02478 |
| Rosa T. Vargas | F | 1979-05-11 | Cambridge | MA | 02140 |
| Mary G. Sullivan | F | 1981-12-09 | Cambridge | MA | 02138 |
| William F. Weld | M | 1945-07-31 | Cambridge | MA | 02138 |
| Henry L. Bowditch | M | 1950-08-05 | Cambridge | MA | 02139 |
| Helen S. Whalen | F | 1973-02-28 | Cambridge | MA | 02140 |
| Vincent J. Carmichael | M | 1976-10-22 | Cambridge | MA | 02138 |
| Charles D. Baker | M | 1956-11-13 | Swampscott | MA | 01907 |
| Lawrence T. Easton | M | 1957-03-17 | Cambridge | MA | 02141 |
| Jane M. Swift | F | 1965-02-24 | Williamstown | MA | 01267 |
| Edward T. Petrillo | M | 1953-12-08 | Cambridge | MA | 02140 |
| Robert C. Aldrich | M | 1962-04-22 | Cambridge | MA | 02138 |
| Helen K. Brennan | F | 1981-10-29 | Cambridge | MA | 02139 |
| Janet R. Holden | F | 1972-04-12 | Cambridge | MA | 02138 |
| Peter F. Donovan | M | 1944-09-12 | Cambridge | MA | 02141 |
| Roger D. Quincy | M | 1948-02-11 | Cambridge | MA | 02142 |
| Albert P. Mehrtens | M | 1959-07-08 | Cambridge | MA | 02142 |
| Bruce K. Hollister | M | 1971-02-06 | Cambridge | MA | 02138 |
| Doris E. Quincy | F | 1983-04-05 | Cambridge | MA | 02142 |
| Norman P. Fielding | M | 1962-11-19 | Cambridge | MA | 02140 |
| James P. Bellamy | M | 1958-08-30 | Cambridge | MA | 02139 |
| Margaret B. Yates | F | 1971-10-22 | Cambridge | MA | 02139 |
| Susan H. Day | F | 1990-11-15 | Cambridge | MA | 02141 |
| Maria E. Cole | F | 1985-03-08 | Cambridge | MA | 02139 |
| Anthony N. Sweeney | M | 1939-03-25 | Cambridge | MA | 02142 |
| Patricia J. Reilly | F | 1976-08-21 | Cambridge | MA | 02142 |
| Frank G. Lansing | M | 1964-01-30 | Cambridge | MA | 02139 |
| Stephen H. Maddox | M | 1981-05-17 | Cambridge | MA | 02141 |
| Edward J. King | M | 1925-05-11 | Winthrop | MA | 02152 |
| Diane S. Atwood | F | 1969-03-14 | Cambridge | MA | 02140 |
| Joan L. Carmody | F | 1988-06-17 | Cambridge | MA | 02141 |
| Vincent A. Pell | M | 1959-07-08 | Cambridge | MA | 02142 |
| Barbara K. Lynch | F | 1965-05-13 | Cambridge | MA | 02139 |
| Joyce A. Whitman | F | 1976-12-05 | Cambridge | MA | 02141 |
| Ruth N. Ackerman | F | 1977-11-14 | Cambridge | MA | 02138 |
| Marcus W. Ellsworth | M | 1966-11-19 | Cambridge | MA | 02140 |
| Janet F. Ortiz | F | 1980-08-19 | Cambridge | MA | 02141 |
| Charles K. Riley | M | 1947-11-04 | Cambridge | MA | 02140 |
| Sandra L. Petty | F | 1973-08-21 | Cambridge | MA | 02138 |
| Walter B. Crowley | M | 1955-06-19 | Cambridge | MA | 02141 |
| Carolyn B. Tighe | F | 1984-04-17 | Cambridge | MA | 02142 |
| Daniel R. Holcomb | M | 1972-09-12 | Cambridge | MA | 02138 |
| Linda B. Park | F | 1968-09-23 | Cambridge | MA | 02140 |
Using the redacted text from Protegrity-PII, as the attacker, we essentially can do next to nothing malicious. The only thing we are able to extract is that a former Governor visited this particular hospital. From OPF’s redacted text, however, the unredacted tokens Cambridge, Governor, Massachusetts, and M give an attacker exactly the columns they need to query the two databases above. Let us walk through it.
Step 1. Filter DB1 to former male governors of Massachusetts.
SELECT name, dob FROM DB1
WHERE state_served = 'MA' AND sex = 'M';The total search space shrinks to 14.
14 candidates from DB1
| name | dob |
|---|---|
| Christian A. Herter | 1895-03-28 |
| Edward J. King | 1925-05-11 |
| William F. Weld | 1945-07-31 |
| Michael S. Dukakis | 1933-11-03 |
| Foster Furcolo | 1911-07-29 |
| Charles D. Baker | 1956-11-13 |
| Francis W. Sargent | 1915-07-29 |
| W. Mitt Romney | 1947-03-12 |
| Deval L. Patrick | 1956-07-31 |
| Robert F. Bradford | 1902-12-15 |
| Paul A. Dever | 1903-01-15 |
| Maurice J. Tobin | 1901-05-22 |
| Endicott Peabody | 1920-02-15 |
| John A. Volpe | 1908-12-08 |
Step 2. Filter DB2 to male residents of Cambridge.
SELECT name, dob, zip FROM DB2
WHERE city = 'Cambridge' AND sex = 'M';The total search space shrinks to 21.
21 candidates from DB2
| name | dob | zip |
|---|---|---|
| Charles K. Riley | 1947-11-04 | 02140 |
| Anthony N. Sweeney | 1939-03-25 | 02142 |
| Albert P. Mehrtens | 1959-07-08 | 02142 |
| Lawrence T. Easton | 1957-03-17 | 02141 |
| Peter F. Donovan | 1944-09-12 | 02141 |
| Daniel R. Holcomb | 1972-09-12 | 02138 |
| Edward T. Petrillo | 1953-12-08 | 02140 |
| Bruce K. Hollister | 1971-02-06 | 02138 |
| William F. Weld | 1945-07-31 | 02138 |
| Norman P. Fielding | 1962-11-19 | 02140 |
| Marcus W. Ellsworth | 1966-11-19 | 02140 |
| Vincent A. Pell | 1959-07-08 | 02142 |
| Vincent J. Carmichael | 1976-10-22 | 02138 |
| Roger D. Quincy | 1948-02-11 | 02142 |
| Frank G. Lansing | 1964-01-30 | 02139 |
| Henry L. Bowditch | 1950-08-05 | 02139 |
| Robert C. Aldrich | 1962-04-22 | 02138 |
| George N. Yost | 1952-04-15 | 02139 |
| James P. Bellamy | 1958-08-30 | 02139 |
| Walter B. Crowley | 1955-06-19 | 02141 |
| Stephen H. Maddox | 1981-05-17 | 02141 |
Neither filter on its own is enough. 14 governors and 21 Cambridge men are still somewhat anonymized crowds. When we use a join however, we see as the attacker the critical identifier.
Step 3. Inner join the two filtered sets on (name, dob).
SELECT name, dob FROM db1_filtered
INNER JOIN db2_filtered USING (name, dob);We have now collapsed into a single row.
| name | dob |
|---|---|
| William F. Weld | 1945-07-31 |
The patient is Governor William F. Weld1! Note that the date of birth here was never present in either database query input. It falls out of the join because exactly one ex-Governor of Massachusetts also appears on the current Cambridge residential roll, and that one row carries a dob field that now ties the redacted clinical event to a specific human being. We still don’t know which day he was admitted, however, we now do know that he was in the hospital. This toy example exemplifies how a misaligned PII detector can result in the extraction of knowledge about the status of an individual, that was otherwise meant to be kept private. Maybe in this case, the attacker cannot do too many malicious things, but the precedent here is set. We now move on to more holisitic evaluations of Protegrity-PII and OPF.
Benchmarks (PII-300k, SPY, Healthcare)
For a standardized quantitative assessment, we run both our internal PII classifier (Protegrity-PII) and OPF model on three total datasets: the two benchmarks from OPF’s model card, plus a novel in-house healthcare set generated by our synthetic data pipeline that serves as a stringent out-of-distribution test for both detectors, and is designed to represent realistic text in the form of logs and correspondence that a PII detector would see in production. Below we characterize all three datasets used.
ai4privacy PII-Masking-300k. PII-Masking-300k is the public, openly-licensed synthetic dataset released by ai4privacy on HuggingFace. It contains roughly 300,000 multilingual examples spanning 6+ languages and a little over 30 PII categories, each with character-level span annotations. It is the de-facto public benchmark for token-classification-style PII detectors and is the dataset OPF reports its headline numbers on.
SPY. SPY is the second benchmark OPF reports against in their model card. Released by Savkin et al. (NAACL 2025), it contains roughly 10,000 synthetic records, primarily consisting of medical consultations legal questions. It covers seven PII categories with token-level BIO annotations and is explicitly designed to expose the gap between generic name-entity-recognition (NER) and fine-grained PII detection on more production-realisitic text for the healthcare and legal domains.
Healthcare specific set. Finally, we built a novel healthcare dataset in-house using our newly developing synthetic data generation pipeline. The pipeline produces realistic hospital correspondence, including things like clinical letters, billing receipts, lab-result summaries, referral notes, consent forms, and memos and contains PII from over 30 categories (using the same entity list as PII-Masking-300k). This set is almost surely unseen from OPF’s model training and is certainly unseen from ours.
It is important to note that our Protegrity-PII classifier and synthetic data pipeline produce a more fine-grained label set than OPF does. As such, for a fair comparison, we collapse our labels down to match OPF’s taxonomy, with the concrete mapping in the Appendix. The point is to make sure OPF is never penalized for emitting a coarser label than the dataset annotates, so any remaining gap reflects real detection ability rather than a mismatch in taxonomies.
Public benchmarks: PII-300k and SPY
We start with the two public benchmarks that OPF reports on directly in their model card. These are the most apples-to-apples comparisons available, since OPF validated against them. Reaching parity here is roughly the expected outcome for a competent detector, at the very least.
Metrics
We use two metric families on these datasets, span-level and token-level, and within each family we report a strict and a relaxed variant. Below are their definitions and an illustrative Figure to demonstrate them.
Span-level metrics. A span is a contiguous character range in the source text together with a label, e.g. (start=142, end=158, label=PRIVATE_PERSON), where start and end refer to index location in a source text, and label indicates the type of PII (see Figure above). We refer to the true locations of start and end as the gold boundaries. Strict requires the predicted boundaries to match the gold boundaries exactly. Relaxed uses span-containment, where any character-level overlap with a compatible gold span counts as a hit. The relaxed number is the one OPF reports on its model card and is the headline span metric throughout their post. Span-level metrics, such as span-level F1 score, is the natural metric for downstream redaction and encryption workflows.
Token-level metrics. Token scoring breaks the document into whitespace-delimited tokens, assigns each token its majority-character gold label (true entity label), and asks the model to label each token independently. Strict is multi-class token F1, where every token must receive the correct PII type from the list of supported entities for detection. Relaxed is binary token detection, where a token is scored as correct if it is flagged as PII at all, regardless of type. As in span-level, the relaxed metric for token-level F1 score is exactly what OPF reports in their model card.
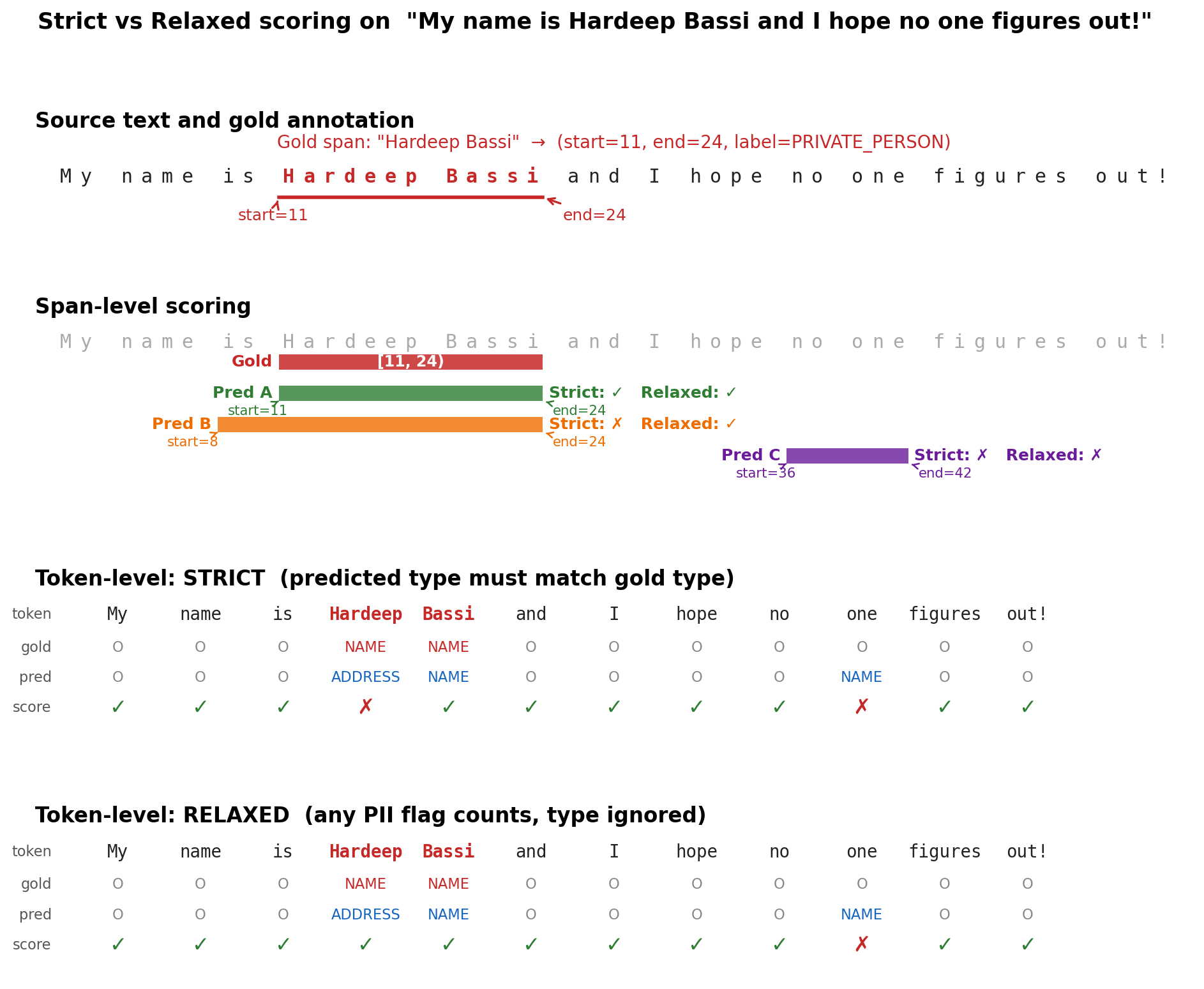
To make the four variants concrete, consider the toy sentence My name is Hardeep Bassi and I hope no one figures out! with a single gold span on Hardeep Bassi. The Figure above walks through what each scoring rule rewards and penalizes on this example.
At the span level, an exact-boundary prediction passes both strict and relaxed conditions for span-level (green), whereas a prediction that overlaps the gold span but starts at the wrong character (orange) fails strict but passes relaxed, and a prediction that lands somewhere else in the sentence fails both (purple). At the token level, mislabeling Hardeep as ADDRESS is a strict miss but a relaxed hit since the token was still flagged as PII, while a false positive on one is wrong under both notions.
We now evaluate the performance on both public benchmarks. All numbers below are F1 scores using strict and relaxed notions define above.
Performance ai4privacy PII-Masking-300k
| Span F1 (OPF) | Span F1 (Protegrity-PII) | Token F1 (OPF) | Token F1 (Protegrity-PII) | |
|---|---|---|---|---|
| Strict | 0.59 | 0.91 | 0.95 | 0.92 |
| Relaxed | 0.92 | 0.92 | 0.96 | 0.98 |
SPY
| Span F1 (OPF) | Span F1 (Protegrity-PII) | Token F1 (OPF) | Token F1 (Protegrity-PII) | |
|---|---|---|---|---|
| Strict | 0.13 | 0.56 | 0.54 | 0.62 |
| Relaxed | 0.44 | 0.58 | 0.56 | 0.62 |
Let us digest what these results mean. First, we notice the obvious gap between strict and relaxed span-level F1 for OPF on both datasets. This gap means OPF is able to find text that contains the PII it is trying to detect, but is consistently off on boundaries (we found most commonly that this is a stray whitespace character). An example of this would be in the sentence My name is John Smith and I ran today., their model labels [whitespace] John Smith as a person, as opposed to John Smith. In contrast, our Protegrity-PII classifier’s strict and relaxed span-level F1 scores are tightly clustered, so the boundaries we detect land where the truly are within the text (i.e. in the previous example, labeling John Smith). Second, on the headline relaxed metrics the two models are comparable on PII-300k and Protegrity-PII leads on SPY. Finally, at a token-level, we see a smaller gap. For PII-300k, we suspect that the slightly better performance in strict token-level for OPF stems from having to collapse our supported entity span list space into theirs. However, on the SPY dataset, we see dominating performance from Protegrity-PII. In general, we view the SPY gap in the token- and span-level metrics as the more meaningful gap between Protegrity-PII and OPF as SPY is almost certainly out-of-distribution for both for OPF, and is out-of-distribution for Protegrity-PII.
Healthcare
The public benchmarks tell us how the two models compare on data OPF was tuned and evaluated against in their model card. However, they tell us comparatively little about how either model behaves on realistic enterprise correspondence. For domains like healthcare and finance, this is the regime that matters for production deployments. To probe this regime, we evaluated both models on the in-house healthcare set developed by our novel synthetic data generation pipeline, as described previously. This dataset was not seen during training by either system, so it serves as a stringent, strongly out-of-distribution test for both models.
We report the same span-level and token-level F1 metrics, this time using only the relaxed of both metrics and visualized as figures instead of tabulated.
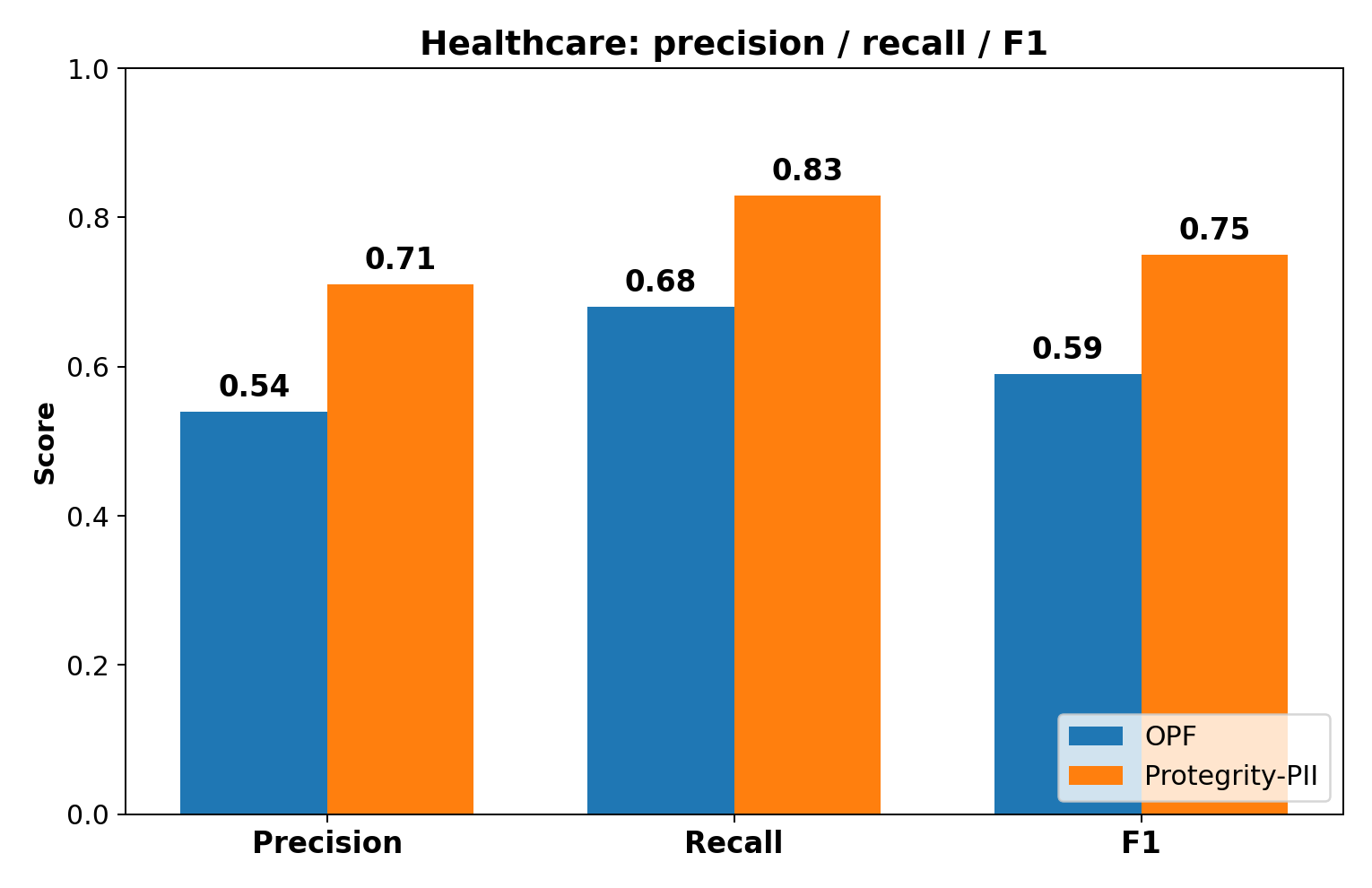
Above, we see that the overall span-level metrics on the healthcare dataset put Protegrity-PII ahead on both precision and recall (and consequently F1). OPF’s lower F1 reflects its difficulty generalizing to the kinds of text we curated for the healthcare set, which were designed to mirror realistic scenarios like hospital receipts and internal chat logs between staff. In contrast, Protegrity-PII handles these formats reliably, suggesting that our model is able to capture the messiness and variety of real healthcare text in a way OPF’s does not.
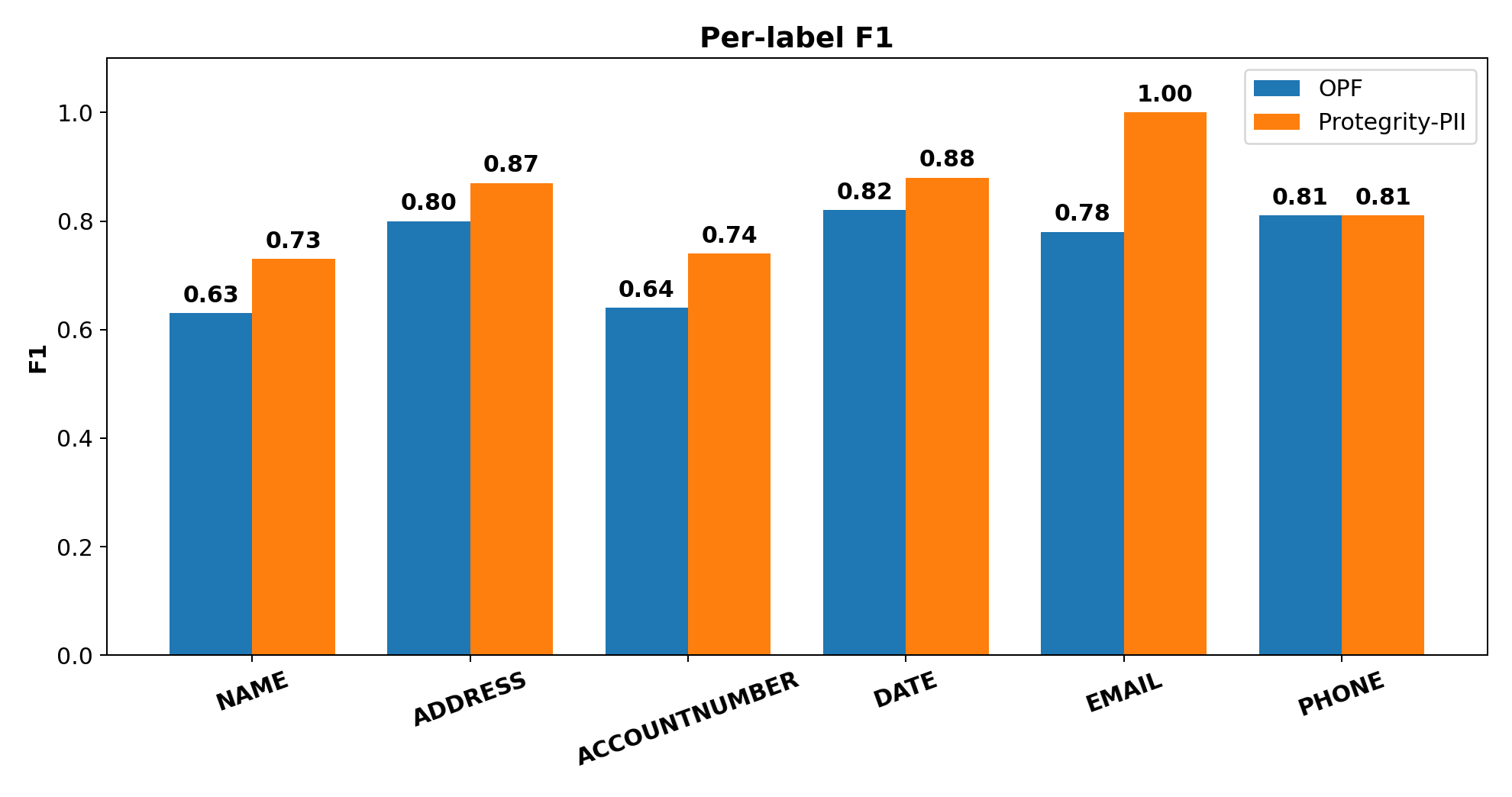
To investigate further, we can break the span-level F1 score down by supported entity list labels to see whether or not Protegrity-PII’s dominance can be attributed to a single label, or is general across the board. We see in the Figure above that is in fact the case that we exceed performance on all labels, and match only on a single one (PHONE).
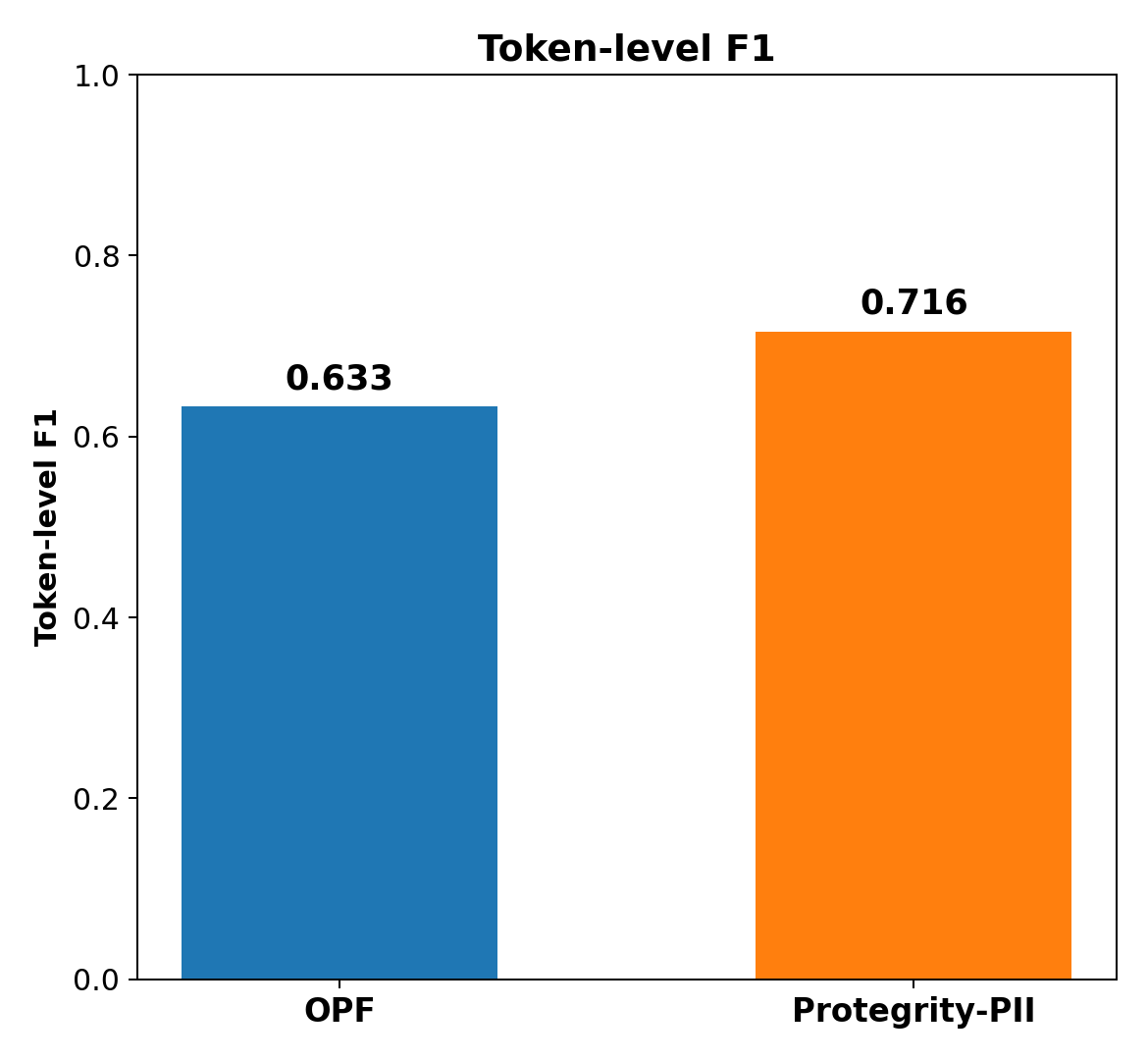
Above, we now look into the token-level performance on the healthcare dataset. Again, we see that the token-level F1 score tells the same story. Protegrity-PII again leads, and because token F1 is invariant to span boundaries, the gap here is purely about which detected entities got flagged by either model. This confirms that the underlying coverage of detected PII is genuinely higher from Protegrity-PII.
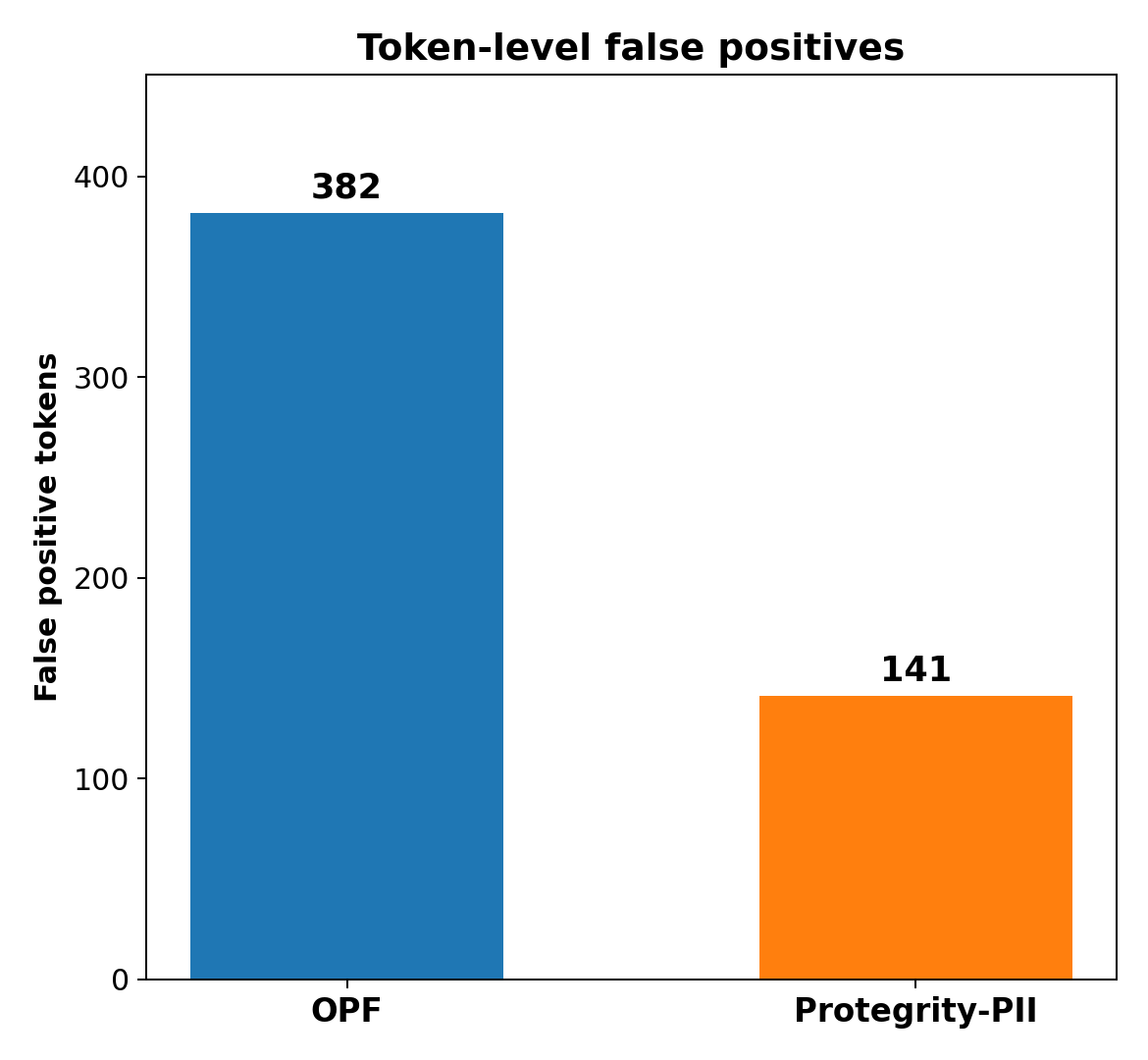
Finally, we investigate the false positive rate for both models, because a usable PII detector has to balance catching real PII with not overflagging genuine text that customers actually need to keep. In the Figure above, we see that OPF flags substantially more non-PII characters as PII than Progerity-PII, which directly explains why its precision lags from the span-level metric Figure previously.
Latency
The span-level and token-level metrics aforementioned are only one of several legs that determine whether a PII detector is usable in production. Another important leg that we have yet to investigate is the efficiency–accuracy tradeoff, which is broadly the relationship between how accurate a model is and what it costs to run that accurately at production volume. In practice, this tradeoff is what eliminates most candidate models long before quality alone does, since a large model tends to be more accurate but slower and more expensive to run, and a small model tends to be faster and cheaper but loses ground on quality. In other words, if a model is more accurate, but takes 10x longer to run, is it really useful in deployment? The useful PII detector is the one that lands in a sensible spot on all of those axes at once rather than maxing out any single one. Let’s focus our discussion here efficiency aspect, and specifically regarding latency of both Protegrity-PII and OPF.
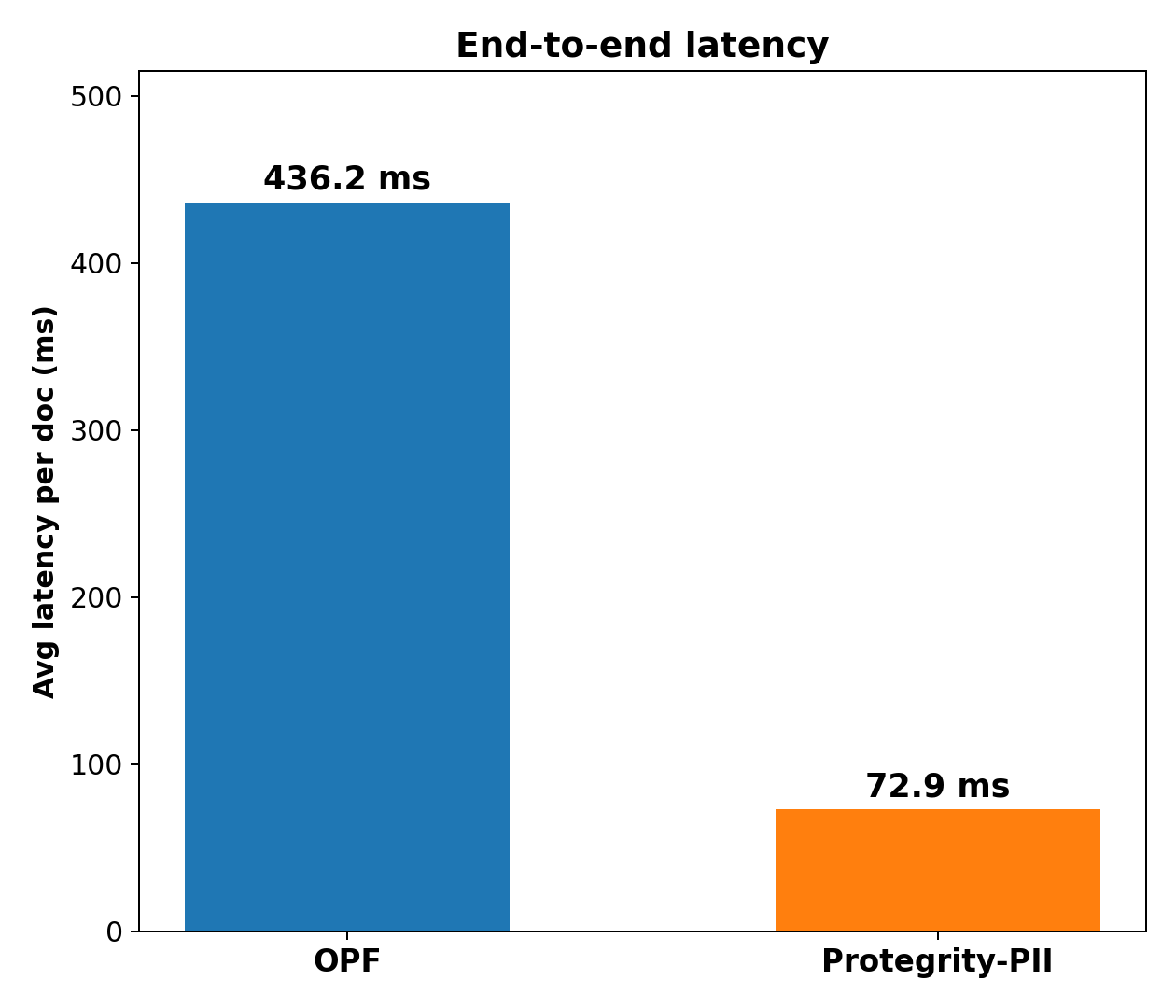
From the Figure above, we see that OPF averages about 436 ms per document on our healthcare set while our model averages about 73 ms on the same hardware and the same inputs. This is roughly a 6x reduction in wallclock runtime. Primarily, we attribute this speedup to differences in the inference stack rather than model size. Protegrity-PII actually has more active parameters than OPF (125 million vs OPF’s claimed 50 million active out of 1.5 billion total), but it runs on ONNX, which gives various optimizations for a more efficient runtime than OPF’s stock PyTorch path. We found that OPF is not straightforward to put on the same footing off the shelf. It’s use of mixture-of-experts (MoE) and dynamic mask shapes break both torch.onnx and optimum, so getting it onto a comparable ONNX serving path is non-trivial.
Cost
Finally, we investigate the cost per 1K characters processed for each model. For OPF, we see that there is a $0.000287 cost per 1K characters, in contrast to Protegrity-PII’s cost of $0.000004 per 1K tokens, when ran on a g4dn.2xlarge EC2 instance, which uses an NVIDIA T4 16GB GPU. We see from this that our model is roughly 2 order of magnitude cheaper to run.
Discussion
The benchmark numbers above tell us how much the two models disagree, but in isolation, they don’t really tell us why. In general, this interpretation problem is ubiquitous across all ML tasks in every field, and many formalisms and interpretations are offered by researchers and authors alike to explain the phenomenona they observe. To answer the discrepancy between Protegrity-PII and OPF, we read through the cases where the two models predicted differently and looked for patterns. Here’s our take from a few that stand out. Spoiler: it all ties back to data.
Let’s look at the following example from our healthcare dataset below:
Test set healthcare letter example
source text:
Consent verification was confirmed through cross-reference with the
national health system identification card number (IDCARD: NHS-987654321),
which remains valid and unrevoked as of this date. Given her sustained
clinical stability and continued willingness to participate, we affirm
that Ms. Smith meets all inclusion criteria under the study protocol.
Respectfully submitted,
Diane Walters
Senior Clinical Epidemiologist
Brown Inc
===============================================================
OPF:
[ACCOUNTNUMBER|BIC|CCN|IBAN] “NHS-987654321”
[NAME] “Ms. Smith”
[NAME] “Diane Walters”
===============================================================
Protegrity-PII:
[IDCARD] “NHS-987654321”
[NAME] “Smith”
[NAME] “Diane Walters”
[COMPANYNAME] “Brown Inc”
===============================================================Taxonomy issues. OPF’s eight-category label set is naturally coarse grained. In fact, it is coarse in ways that lose information users actually need. ACCOUNT_NUMBER is the likely the clearest example. In their taxonomy, it conflates national health IDs, MRNs, IBANs, BICs, credit card numbers, and arbitrary internal account identifiers into a single bucket. For a redaction pipeline this might be acceptable, but for any downstream consumer that wants to apply different policy to, say, a credit card vs an internal patient ID, this coarseness is an active detriment, since you are obfuscating your own downstream task! Similarly, PRIVATE_PERSON collapses individual names with company names, and in many examples (such as the test set example shown previously), we see that OPF is unable to make this distinction.
Context-dependent PII. A more subtle failure mode is that OPF, like most detectors trained on span-annotated synthetic data, learns to recognize the visual signature of canonical PII rather than the underlying concept of identifying information. Tokens that only re-identify someone when read in context tend to slip through. Hence, an isolated city name like “Cambridge” (see the Knowledge extraction example) will generally be passed through unflagged, despite being PII that can be used to re-identify an individual. This behavior follows fairly directly from how the training data is annotated, and in their own model card, they report the inability to catch addresses that don’t follow a full standard format of [STREET ADDRESS, STREET, CITY, COUNTRY, ZIPCODE].
Conservative on rare/structured identifiers. OPF reliably flags credit card numbers, IBANs, and email-shaped strings, but is noticeably less consistent on domain-specific identifiers that don’t match a common regex profile such as internal patient IDs and insurance claim codes. In contrast, our model, trained on data that explicitly covers these shapes, picks them up reliably. This segues nicely into the final point.
Data holds the weight. This is the single most important point that we wish to emphasize. PII detection is a data problem far more than a modeling problem . The model choice matters at the margin, but the difference between a usable production-grade PII detector and a brittle one comes down to quality of the annotation of the dataset and the range of formats covered in the training set. Critically, OPF released weights and model design of within their model card paper but not the training corpus or data generation pipeline! That means when we see OPF systematically miss something, we cannot tell whether it’s a coverage gap in their data or a modeling artifact. We can only observe the symptom. For users trying to decide whether OPF will work on their domain, this is a real problem as there is no way to predict failure modes from the model card alone. Empirical experiments must be ran at scale and it’s hard to pinpoint exactly where the failure comes from. In contrast, we can systematically determine from our procedure if the problem arises from a training-test distribution mismatch or a model failure.
Conclusion
One could glance at the tables above, treat this as a scoreboard, hand Protegrity-PII the trophy, and walk away, but framing it that way buries the point we are actually trying to make.
In contrast to OpenAI’s release, which only includes the model, here at Protegrity, what we bring to the problem of detecting PII is the model and also the relevant carefully curated and high-quality dataset and pipeline that generated it. This synthetic data generation pipeline is aimed exactly at the kinds of documents enterprise customers can actually send to us: hospital correspondence, billing and claims text, banking statements, legal filings, contact-center transcripts, you name it. The taxonomy that our data generation pipeline and model supports is also far finer than OPF’s eight categories because real downstream policy requires that resolution.
In conclusion, the takeaway here is rather simple and oftentimes lost in conversations regarding model performance or architecture design. Whether the setting is enterprise ML or scientific machine learning, model choice is more often than not secondary to the assembly and deployment of high-quality training data. Historically, this seems to also be the case. Take the transformer architecture itself as the obvious example. It was a genuine breakthrough when it landed in 2017, but on its own it did not produce ChatGPT or Claude. What produced those systems was the same architecture pushed to scale on enormous, carefully curated text corpora and then aligned with human feedback data. The model itself was certainly a key player in the unlock, the data which these systems were trained is really what made those products shine. In our view, PII detection sits in the same place. The hard part of this whole problem comes down to sourcing the right data, getting it labeled correctly, and grinding through enough iterations to cover vast array of forms PII actually takes in real enterprise text.
Appendix: Evaluation setup
For every experiment in this post, we project into OPF’s label space. We primarly opt to do this because OPF emits a deliberately narrow taxonomy of eight categories: PRIVATE_PERSON, PRIVATE_ADDRESS, PRIVATE_DATE, PRIVATE_EMAIL, PRIVATE_PHONE, PRIVATE_URL, ACCOUNT_NUMBER, and SECRET. In contrast, by construction our model and synthetic data generation pipeline incorporate and support a more natural fine grained label taxonomy. For example, our production model distinguishes NAME from COMPANYNAME, STREET from ZIPCODE from CITY, and breaks ACCOUNT_NUMBER into IDCARD, IBAN, BIC, CCN, etc. Similar can also be said for the benchmark datasets.
Concretely: name-like categories (NAME, COMPANYNAME, …) collapse to PRIVATE_PERSON; address-like categories (STREET, CITY, ZIPCODE, …) collapse to PRIVATE_ADDRESS; identifier-like categories (IDCARD, IBAN, BIC, CCN, ACCOUNTNUMBER, …) collapse to ACCOUNT_NUMBER; and DATE, EMAIL, PHONE, URL map straight through. Categories with no OPF analogue are excluded from scoring on both sides. This deliberately throws away signal that our model and the gold annotations actually contain. For example, a name flagged as COMPANYNAME vs NAME is treated as identical post-projection. Consequently, this ensures OPF is never penalized for emitting a coarser label than the dataset annotates, and that any remaining gap reflects detection ability rather than taxonomy mismatch.
1This test case was of course inspired by the famous result from a 1997 data privacy study where graduate student Latanya Sweeney demonstrated that ~87% of the U.S. population could be uniquely identified using only ZIP code, gender, and date of birth. She used this to famously reidentify Governor William Weld’s confidential medical records by linking them with a voter database.