A Zero Trust Framework for Safer, Enterprise-Ready LangGraph AI Pipelines
Building a Dual-Gate Architecture with Protegrity Data-Centric Semantic Protection
If you’ve been building in the generative AI space lately, you already know the vibe: we’ve officially graduated from simple, single-prompt chatbots.
Today, we’re building autonomous, multi-step agentic systems. Frameworks like LangGraph have changed the game for developers, making it easier to orchestrate complex, stateful loops where data flows from vector databases to LLMs, and then out to external APIs. It’s powerful, it’s fast, and it is easy to see how it all comes together.
But here is the elephant in the room: how are you protecting the sensitive data moving through those loops?
When data moves recursively through a graph — looping, branching, and updating a shared memory state — traditional security perimeters can fall apart. To safely put agentic workflows into production, enterprises need a strict Zero Trust mindset: never trust, always verify, and always assume a breach is already happening.
Let’s break down why this matters and, more importantly, how we can address it by pairing LangGraph with Protegrity’s data-centric semantic protection.
The “4 Whys”: The Real-World Case for Advanced AI Semantic Protection
Whenever we talk about upgrading security architecture, we ask four fundamental questions. Here is the “why” behind securing graph-based AI.
Why Change?
Modern AI graphs increase PII exposure across interactions, making traditional point-in-pipeline controls fundamentally ineffective and leaving organizations broadly vulnerable.
Why Now?
Agentic behavior and observability tooling transform data governance risk from a future planning item into an immediate operational challenge that cannot be deferred.
Why Protegrity?
Protegrity secures data at the pipeline boundary and inside AI graphs, regardless of topology complexity — linear, branching, or recursive — using a graph-native, dual-gate architecture.
Why It Matters?
Organizations can scale AI innovation with confidence, maintaining compliance, preserving customer trust, and turning data security into a durable competitive advantage.
Under the Hood: The Dual-Gate Architecture
So, what does this actually look like in practice? We recommend implementing a Dual-Gate Security Architecture. It’s a clean design pattern where sensitive data is semantically protected the moment it enters your system, and only unprotected when absolutely necessary at the very end.
Gate 1: Ingress Semantic Protection
Before a user’s query or an enterprise data stream ever touches your central LangGraph pipeline, it goes through Gate 1. Protegrity scans the incoming payload for PII, financial identifiers, or credential strings. Protegrity Guardrails can block the incoming payload, or sensitive values can be immediately replaced with semantically protected values. If a user types a Social Security number or credit card number, the LLM only sees a semantically protected placeholder that looks and behaves like real data, but holds zero value to an attacker.
Inside the Zero-Exposure Zone: LangGraph Core Orchestration
Now, your LangGraph pipeline can do what it does best — orchestrate your business logic — but entirely within a semantically protected universe:
- Secure Multi-Source Retrieval: Your vector databases and SQL indices work with pre-protected keys, ensuring your underlying data pools stay protected.
- LLM Reasoning Isolation: The model processes prompt templates using semantically protected values, helping prevent application logs, tracing tools, and fine-tuning datasets from accidentally caching actual corporate secrets.
- Tool and Context Persistence: Even if an agent loops through multiple tools, the shared state remains protected.
The Visual Architecture Flow
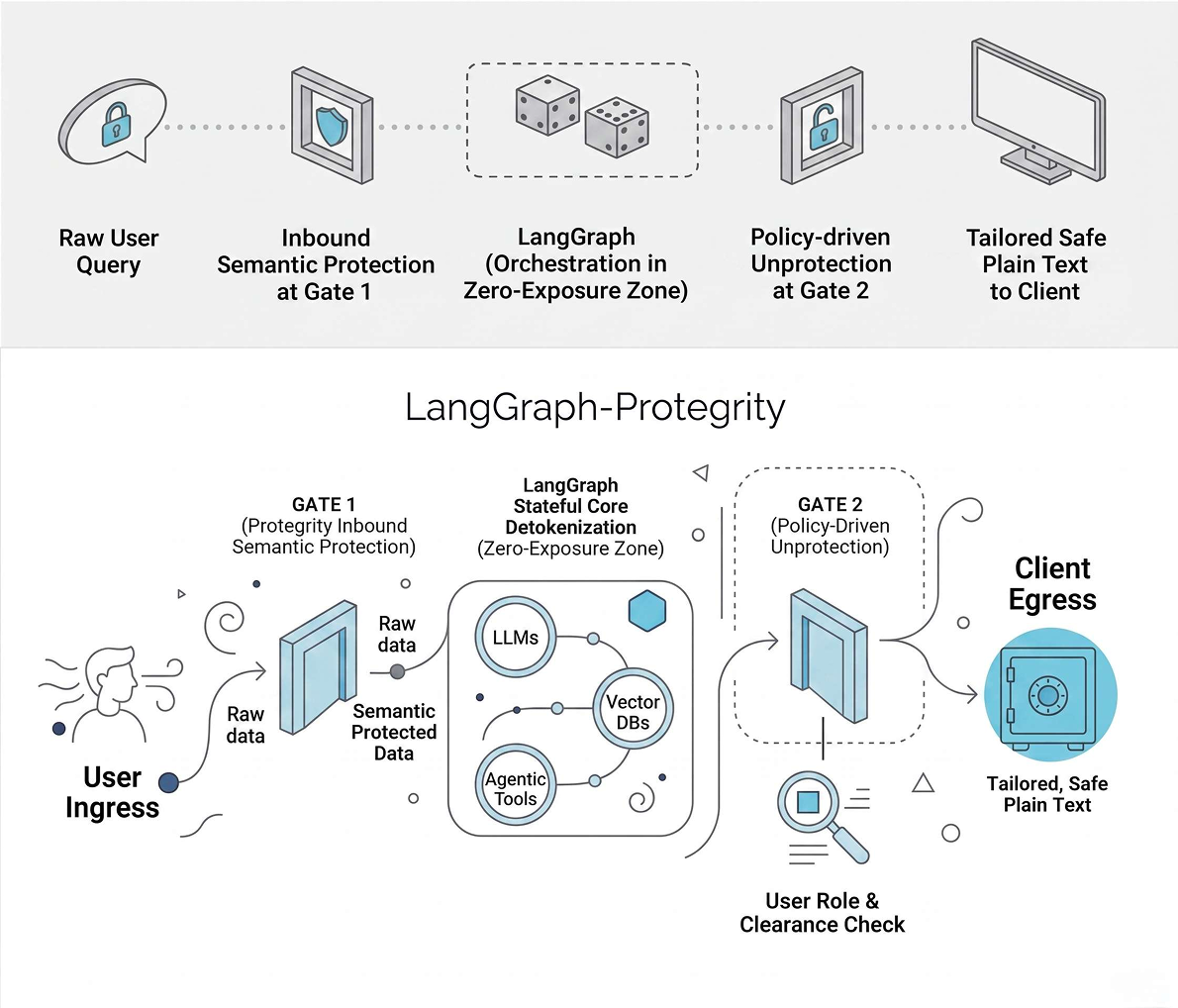
Gate 2: Policy-Driven Unprotection
Once your LangGraph pipeline finishes its job and outputs a final response, it passes through Gate 2. This is where Protegrity checks the context and the identity of the person receiving the output:
- Privileged users, such as a finance manager, can receive securely unprotected strings when policy allows them to see the actual sensitive data.
- Unprivileged users, such as a support agent or external client, receive masked variations or standard placeholders, enforcing the principle of least privilege.
The Takeaway
LangGraph gives developers the tools to build smart, dynamic, and stateful AI systems. But as creators, it is on us to build those systems responsibly.
By embedding data-centric security directly into the pipeline lifecycle, enterprises do not have to choose between cutting-edge AI features and strong compliance controls. They can get the best of both worlds: a highly intelligent agentic system that is secure by design.
Take a look at the Protegrity AI Developer Edition Zero Trust Orchestrator Reference.
What strategies are you using to protect your data streams in production AI apps? Let’s chat in the comments below.