Ask Anything, Expose Nothing: Text-to-SQL Security
Picture a customer service lead at a bank typing a question into an internal tool, in whatever words come naturally: “What percentage of customers with active loans look likely to miss their next payment?” Seconds later, an answer comes back. No SQL, no dashboard, no ticket to the analytics team. The interface enterprises have wanted for a decade is finally here. The catch is what sits behind that tidy answer.
Natural language is now the front door to enterprise data, and it is already driving real revenue. But the default text-to-SQL pattern wires an unpredictable model straight to your database, with no inspectable step in between and no enforcement preventing the model from talking its way around. The durable fix is structural: let the model propose a plan, let a deterministic compiler validate it, and let data-centric policy protect the data below the model. Semantics without policy is unsafe. Policy without semantics is blind.
The default pattern has no trust boundary
Conversational analytics is not a someday bet; it is already in the revenue. In February 2026, Databricks reported a $5.4 billion run rate, with over $1.4 billion from AI products, and CEO Ali Ghodsi credited Genie, its natural language interface, with driving more usage on the platform.1 Every major warehouse is racing to add the same conversational layer. But in most systems shipping today, the question travels straight from a language model into the database, and whatever SQL the model invents is what runs against production data.
That works in a demo and breaks in production. There is no inspectable step to audit, and the same question can return different answers on different days. But here is where it gets dangerous: a model flattens trusted instructions and untrusted input into a single stream of tokens, so it cannot reliably distinguish a legitimate request from a hostile one. That is why prompt injection sits at the top of the OWASP list for LLM applications: a user, or even a document the model reads along the way, can quietly steer what executes.2
Now, picture this with no human in the loop at all. In the agentic world, an autonomous agent fires these questions itself, chains them together, and acts on the results, all at machine speed. A weakness that was merely risky when a person was typing becomes a runaway one when nobody is watching the wheel. And bolting guardrails onto the output will not save you, since that only catches the failures you thought to anticipate. The problem is structural, not a question of model quality, which is one reason S&P Global found 42 percent of companies abandoned most of their AI initiatives in 2025, up from 17 percent a year earlier.3
The fix: propose, validate, protect
The durable fix is architectural, and it follows a principle established in AI security research, from Simon Willison’s Dual LLM pattern to Google DeepMind’s CaMeL: never let the model’s raw output decide what happens.4 In the Secure Text to Analytics approach that Protegrity and Bodo built together, the model is not allowed to write SQL. It proposes a plan in PyDough, an inspectable language grounded in a knowledge graph of permitted entities, joins, and metric definitions. A deterministic compiler validates the plan before any database is touched and rejects anything that references an unauthorized table, an unapproved join, or a runaway scan. Then Protegrity protects the data underneath: sensitive fields are semantically encrypted, so an unprivileged user sees protected values, realistic stand-ins that carry none of the original information, while still getting the same aggregate answer a privileged user would.
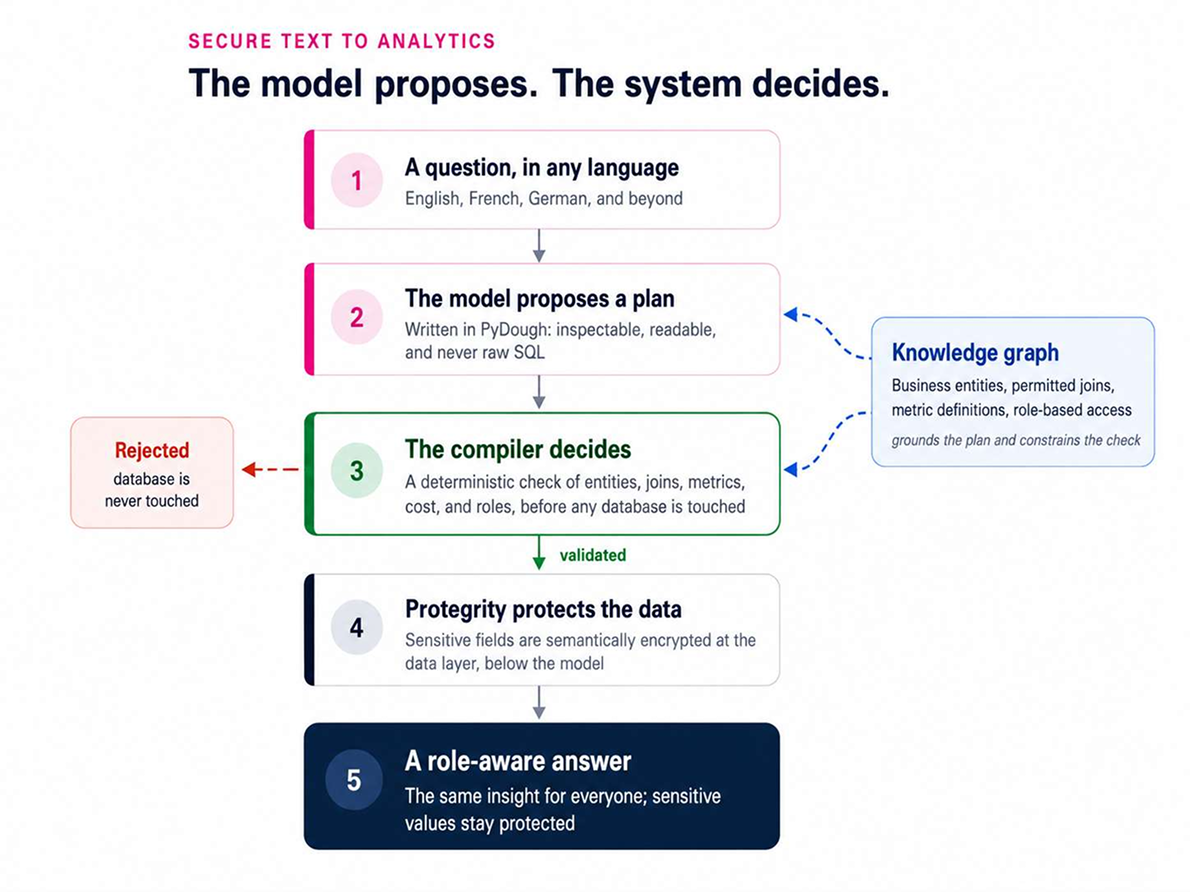
Security through architecture, not good behavior
This is security through architecture rather than good behavior. The model cannot emit dangerous SQL because it cannot emit SQL at all. The compiler will not pass an unapproved plan. The data is semantically encrypted beneath it all, so any leaked value is a protected stand-in, not a name. The layers are independent, so an attacker would have to beat all of them at once. That is what makes the promise real: you can let anyone ask anything, in any language, precisely because safety does not depend on the question being well-behaved. And because enforcement sits outside the model, it holds just as well when an autonomous agent is doing the asking, which is exactly when the blast radius of a wrong decision is largest.
Ask anything you like. Expose nothing you should not.
Sources
- Databricks press release, “Databricks Grows >65% YoY, Surpasses $5.4 Billion Revenue Run-Rate,” February 2026
- S&P Global Market Intelligence survey on enterprise AI initiatives, 2025 to 2026
- OWASP Top 10 for Large Language Model Applications
- Google DeepMind, “Defeating Prompt Injections by Design” (CaMeL), 2025; Simon Willison, “The Dual LLM pattern,” 2023